


Some of our users explained that sometimes the column order in CSV data files they wanted to add to a Data Source was not consistent with the column order in the Data Source. This resulted in data going into quarantine.
We improved Tinybird so that even if the columns are in a different order to the one used when the Data Source was created, you can add data to a Data Source from a CSV, provided, of course, that all the column names are in the CSV header.
Let’s look at an example of appending data to a exiting Data Source of movie likes and dislikes. The original Data Source was created from a CSV with this column order:
Depending on the source of the data and how the CSVs are generated, the order of the columns might not be guaranteed. You could very well find a CSV with the same columns in different order:
This is not a problem since the data will be appended correctly.
Append from the UI
In the UI, to add data the new data to the movies Data Source just select add Data Source and upload the file named movies.csv, where the CSV header contains the column names.
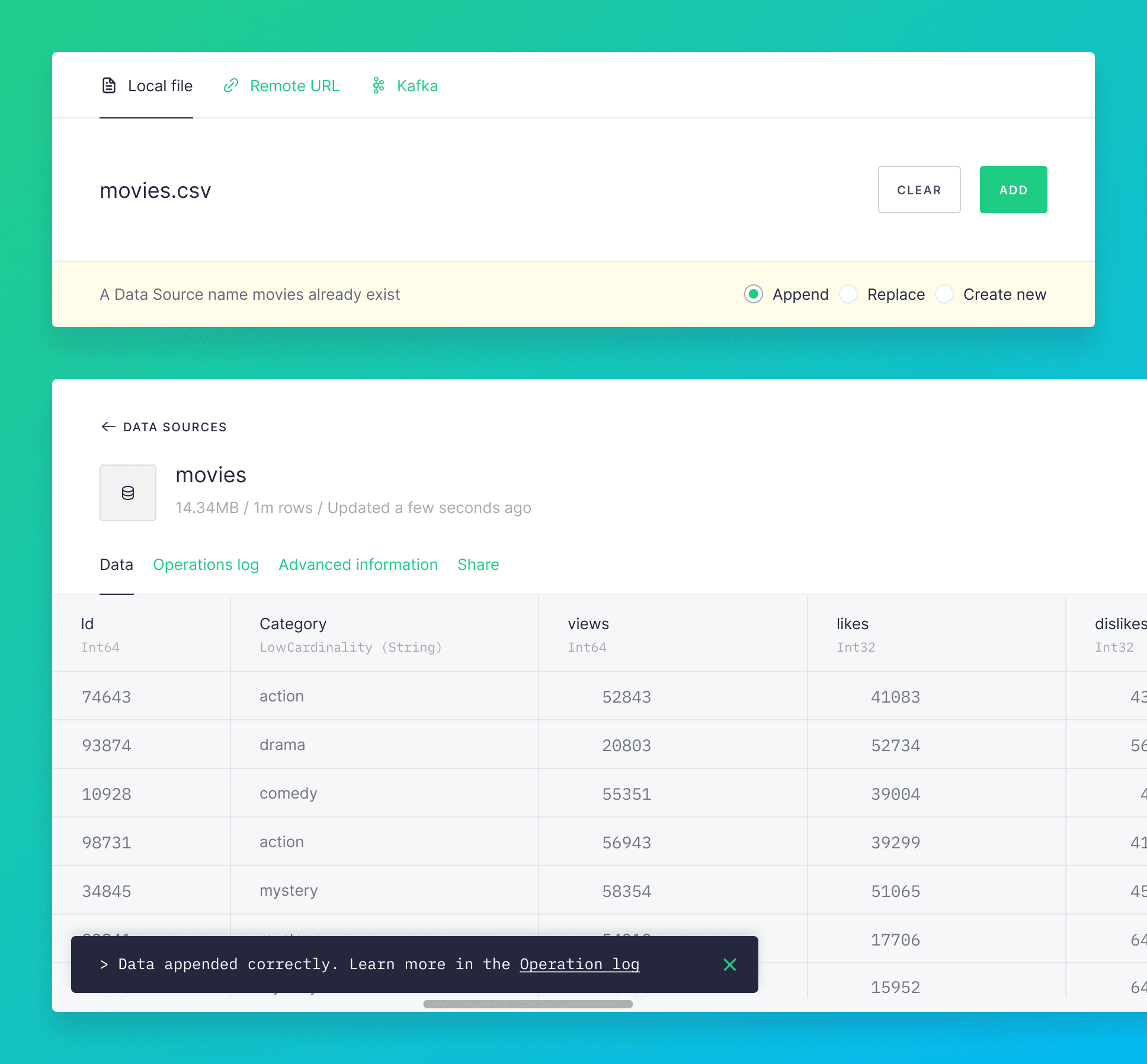
The new data is appended to the movies Data Source.
Append from the API
From the API, to append data into the existing Data Source movies, you specify the mode and the name. The order of the columns doesn’t matter, provided the CSV header contains the column names.
Append from the CLI
From the CLI, append the new data to the movies Data Source without worrying about the column order, provided the CSV header contains the column names.
Login to your account to check this out and tell us what you think in our Slack.