Data Platform

More than just
ClickHouse® in the Cloud

All-in-one managed ClickHouse
Customer proof at scale
Built for teams
focused on shipping
Spend more time shipping features.
achieves 10x fewer cloud costs and an 8x faster development cycles.
users
latency
per month
“I've worked with Hadoop, Spark, Flink... with Tinybird we have achieved in a few days what would have taken ages with any other tooling.”

Guy Needham
Staff Backend Engineer at Canva

Our value proposition
Why Tinybird
clickhouse-setup-plan.md
# Self-hosting ClickHouse
23
ClickHouse database
4Fast queries
5- Provision and manage ClickHouse clusters6- Manual sharding, replication, HA7- Write pipelines + migrations8- Build custom API layer9- Maintain ingestion + backpressure10- Spend weeks on ops# Tinybird
23
ClickHouse database
4Fast queries
5+ Fully managed and serverless6+ Automatic scaling7+ Schema iteration & auto-migrations8+ SQL → API instantly9+ Streaming ingestion with autoscale10+ Incredible support11+ Ship products in days
Built for scale
Everything you
need, included
and an amazing developer experience.
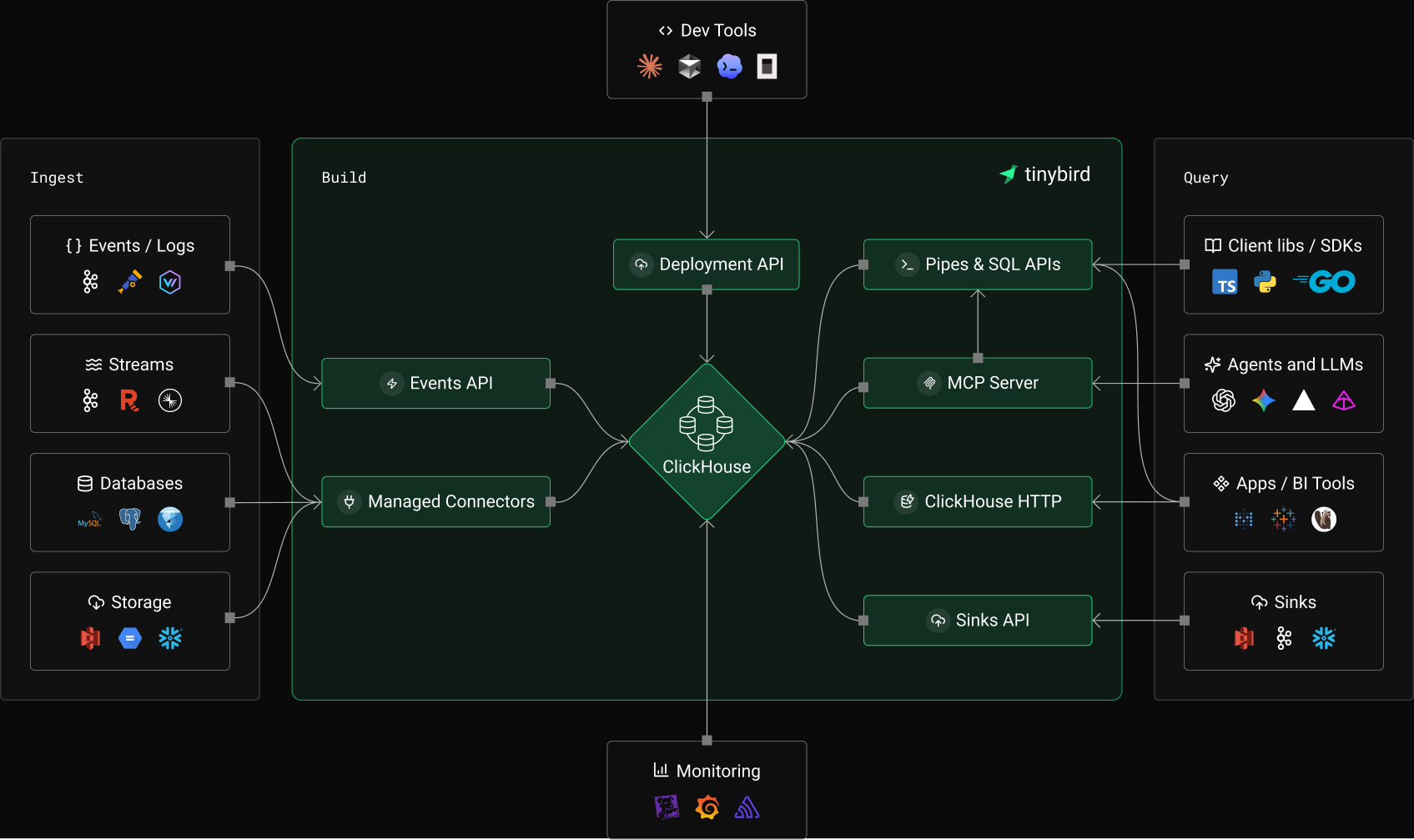
Managed ClickHouse cluster
- Vertical and horizontally scalable
- Unlimited multi cloud storage
- Automatic ClickHouse version upgrades
Ingestion
- Streaming Ingestion APIs
- Enterprise-grade Kafka connector
- Native object storage ingestion
Query & delivery
- Serverless, secure SQL APIs
- Native ClickHouse HTTP interface
- Kafka and S3 sinks
Enterprise-ready
- Private infrastructure and networking
- SLAs and dedicated support
- SOC2 and HIPAA compliant
Developer friendly
- CLI and local development
- Automatic schema migrations logs
- Data branching with Git + CI/CD integration
AI-native
- LLM-ready remote MCP server
- Tinybird Code
- ClickHouse skills for AI agents
* Talk to us for sizing and enterprise requirements
Customer Stories
Built to scale across
your organization

FAQs
How is Tinybird priced?
Tinybird's pricing scales elastically based on compute, so you pay based on the value and insights delivered to your users. Visit our pricing for full details.
Is Tinybird more expensive than hosted ClickHouse?
For production workloads, it's usually cheaper. Tinybird replaces multiple systems (ingestion, streaming, APIs, infra, ops) and removes operational overhead.
Can I start small?
Yes. You can start with a free or developer plan and scale up without re-architecting or managing clusters. For dedicated plans contact sales.
How does Tinybird scale?
Tinybird scales vertically and horizontally, automatically. Compute and storage scale independently, so performance doesn't degrade as data grows.
Can it handle petabyte-scale data?
Yes. Tinybird is designed for low-latency queries on petabyte-scale datasets across multiple teams and use cases.
Is scaling automatic?
Serverless APIs scale automatically, for the ClickHouse cluster you have full observability and cluster management tools to scale both vertically and horizontally.
Is this real ClickHouse?
Yes. Tinybird runs native ClickHouse under the hood.
Can I use standard ClickHouse SQL?
Yes. Tinybird supports standard ClickHouse SQL and the native HTTP interface.
Can I connect my existing tools?
Yes. Any tool that works with ClickHouse (BI tools, notebooks, custom apps) works with Tinybird.
How hard is it to migrate from ClickHouse?
Most migrations are straightforward. Schemas, queries, and data models usually work with minimal changes.
Can I migrate gradually?
Yes. You can run Tinybird alongside your existing setup and migrate workloads incrementally.
Do you help with migration?
Yes. Tinybird provides tooling, documentation, and hands-on support for production migrations.
Is Tinybird enterprise-ready?
Yes. Tinybird supports private infrastructure, secure networking, and enterprise SLAs.
What compliance standards do you meet?
Tinybird is SOC 2 and HIPAA compliant.
How is data secured?
Data is encrypted in transit, with fine-grained access controls and isolated environments.

Ship real-time features from ClickHouse today, guaranteed
- Start with a 10-minute quickstart
- Explore pre built templates
- See what others are building
- Learn how to migrate from ClickHouse

