


AWS cloud tools Kinesis, S3, Glue, and Athena are used commonly together to build data analytics architectures hosted on AWS. The set of tools lets you process long-running and complex analytical queries over data in S3, which works well for business intelligence use cases.
But, I’ve often seen engineers apply this group of cloud tools inappropriately in certain scenarios. In this post, I’ll explain what Kinesis, S3, Glue, and Athena are best suited for, where they fall short in terms of real-time analytics and stream processing, and how to fill that gap on AWS with tools better suited for real-time, operational use cases.
What are Kinesis, S3, Glue, and Athena?
Kinesis, S3, Glue, and Athena are commonly used in architectures running analytical workloads over vast amounts of longitudinal data.
- Amazon Kinesis collects and processes data as it arrives.
- Amazon S3 is a highly scalable, cost-effective object storage solution.
- AWS Glue enables the transformation and enrichment of the data for discovery.
- Amazon Athena is a query engine for analyzing data in Amazon S3 using SQL.
Consider an example with Kinesis, S3, Glue, and Athena
Nikidas is a fictional eCommerce retail company with multiple webstores. Nikidas revenue teams want to understand the health of the sales pipeline by analyzing past sales events.
Step 1 - Nikidas engineers use Kinesis to capture and process event streams created by apps, logs, and services, filtering those streams by event types (clickstreams, stocks, sales) and aggregating them by platform.
Step 2 - Kinesis writes events data to “Sales Events” files in Amazon S3, where they can be stored indefinitely. With Amazon S3, Nikidas engineers create user access control policies, version files to protect them from accidental deletion or modification, and apply lifecycle policies to help control service costs.
Step 3 - Using AWS Glue, Nikidas engineers schedule data transformations, enrich Kinesis streams with other data sources, and build a data catalog so others can understand and discover data.
Step 4 - Using Athena, Nikidas engineers write SQL to create tables and run queries over “Sales Events” files that Kinesis has stored in S3.
Summary: With Kinesis, S3, Glue, and Athena, Nikidas engineers create a data pipeline that can filter and aggregate sales event streams, write them into permanent storage, catalog metadata, and run SQL queries over stored data. This architecture provides separation of storage (S3) and compute (Athena), meaning that the two scale independently; Nikidas doesn’t increase storage costs by increasing compute power.
Where Kinesis, S3, Glue, and Athena sit in the data architecture
Kinesis, S3, Glue, and Athena are tools to handle strategic, business intelligence use cases. They effectively handle long-running and complex analytical queries where response latency and data freshness are not critically important. Most commonly, these use cases are of the "reporting and dashboarding" variety, focused on internal reporting and stakeholder communication.
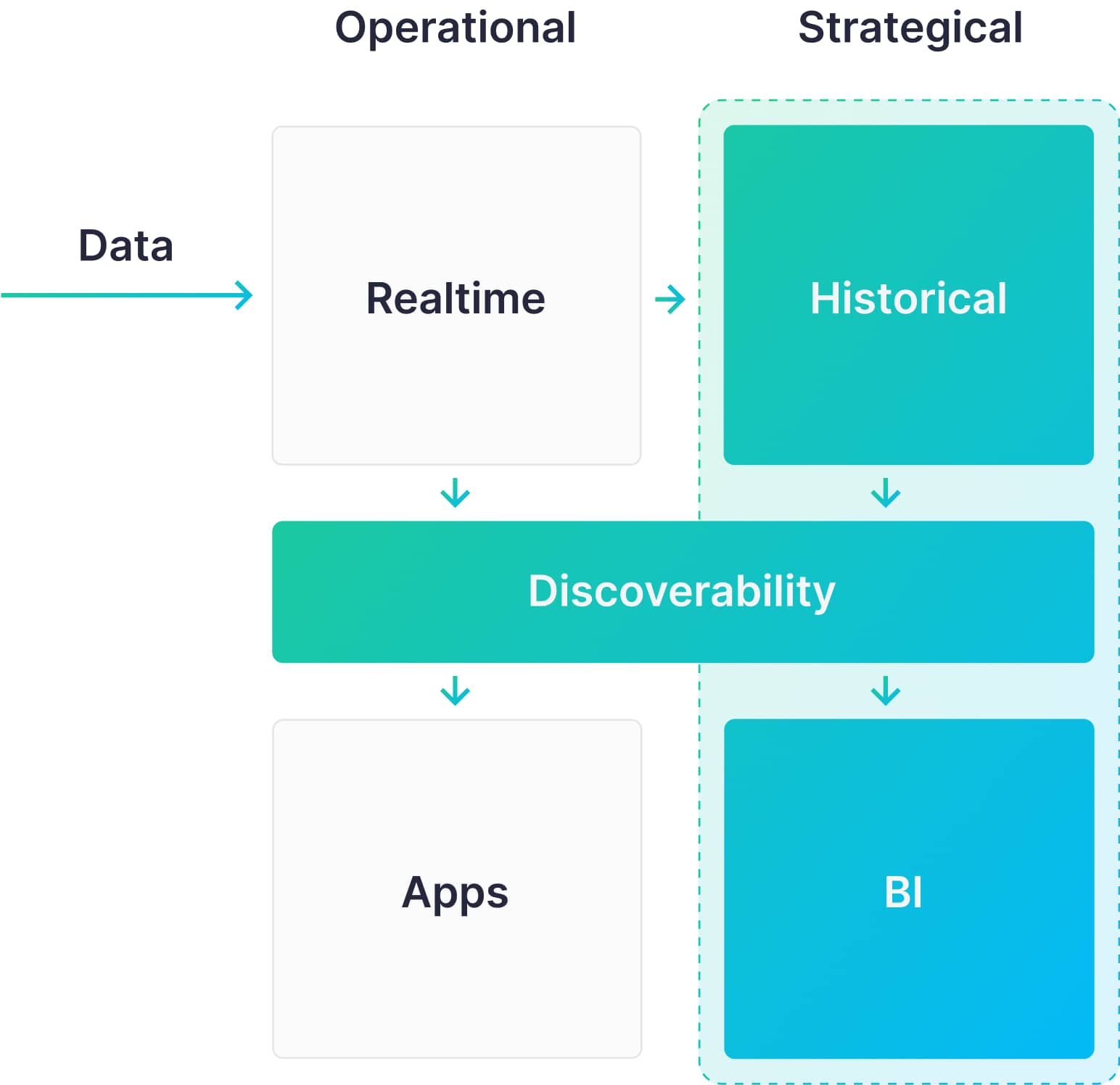
Limitations of Kinesis, S3, Glue, and Athena
Set-up, integration & maintenance: Building this platform requires knowledge of 4 distinct and somewhat complex tools. Fortunately, this architecture is well-documented, so you’re not on your own getting started. There is limited support, however, for debugging and cost optimizations. It’s very possible to engineer your way into a complex and expensive spaghetti monster.
Concurrency: Out of the box, Athena is limited to 20 concurrent queries, and while that can be improved, don’t expect to easily scale from 20 to tens of thousands! S3 has higher concurrency limits, peaking at around 5,500 requests per second per object prefix. You can scale S3 concurrency by partitioning your data with unique object prefixes, but this adds further complexity into your real-time ingestion process. These limitations typically aren’t an issue for business intelligence use cases, but can make this architecture a poor fit for the high-concurrency requirements of user-facing analytics or real-time personalization.
Latency: Athena is perfectly positioned to query flat files stored in S3, and scaling to run those queries over huge data sets - thousands of files and up into the petabytes of data. But its primary purpose is flexibility and scale, not speed. Athena is great for running scheduled reporting, which often occurs outside business hours, but it is not well-suited for interactive applications.
Freshness: The small file problem is a classic issue with distributed, big-data query engines like the AWS architecture (and others like Apache Hive and Impala). For real-time applications requiring up-to-the-second knowledge, you would want to write events to file as soon as they come in. In these architectures, however, small files are the enemy of performance. To avoid this issue, many turn to “batching” - waiting for many events to arrive and then writing them all into a single, larger file. Unfortunately, batching reduces the freshness of data. Queries made in Athena will not be able to access new data until the batch window is filled. Put simply, Athena’s performance will not scale without batching.
How to address these limitations
This set of AWS cloud tools is well suited for applications where freshness, concurrency, and latency constraints are more loosely defined. But if developers want to build applications on top of the analytics generated in this stack, the necessary UX constraints of the products they are building will not be satisfied by Kinesis, S3, Glue, and Athena.
As such, they’ll need to utilize a real-time analytics architecture designed to support the freshness, concurrency, and latency requirements. Tinybird fits the bill here.
What is Tinybird?
Tinybird is a serverless backend for developers building operational applications on top of large amounts of data. It lets you easily ingest data from varied sources, transform and enrich that data with SQL, and expose results to applications via scalable HTTP endpoints.
An example with Tinybrd
Returning to Nikidas, our eCommerce company with multiple webstores. In addition to its analytical reporting requirements, Nikidas wants to give its Sales & Marketing team the ability to measure and improve the impact of revenue-generating campaigns, from advertisements to seasonal sales to product placements, especially as they introduce new variants and tests to the campaigns.
The fundamental question Sales & Marketing must answer is “Are the campaigns we’re running, and the tests we’re introducing, positively impacting product sales right now?” To inform decisions about messaging and ad placement, they need real-time information about campaign-influenced revenue. The sooner they get that data, the more confidence they have that a particular campaign variant actually influenced (or deterred) revenue growth.
Step 1 - Nikidas engineers ingest data into Tinybird using one of several methods. In this case, Sales Events are already being published to a Kafka topic. Nikidas engineers connect the Kafka cluster directly to Tinybird (this could be self-hosted OSS Kafka, Confluence, Cloudera, MSK, or even Kafka-compatible clusters of Redpanda and Pulsar). Tinybird consumes sales events from the topic and stores them in a Tinybird Data Source. There is no need for batching and no artificially-introduced latency.
Step 2 - With raw events data in Tinybird, Nikidas engineers then write transformations and analytical logic using chained, composable SQL nodes called Pipes. Pipes can be used to enrich Sales Events data with campaign metadata and apply filters and aggregations. They can also be used to generate real-time materialized views which incrementally update as new data is ingested, and can be used as a Data Source by subsequent Pipes. As data is ingested into Tinybird, they pass through these Pipes on the fly.
Step 3 - Nikidas engineers publish the results of selected Tinybird Pipes as parameterized HTTP endpoints. This happens with a single click or command; there are no custom libraries or additional frameworks to learn or integrate. The resulting endpoints return results based on the freshest data and can be called by frontend applications or backend services using any HTTP requests library. They scale to handle thousands of concurrent requests with millisecond latency.
Where Tinybird fits into your data architecture
Unlike the AWS tools, Tinybird is fundamentally a platform for building real-time data products and data apps. Where business intelligence applications largely focus on internal stakeholder reporting and observability, Tinybird focuses on creating data products for application development. Tinybird is uniquely suited for cases where product UX needs demand low latency response times on analytical queries over fresh data.
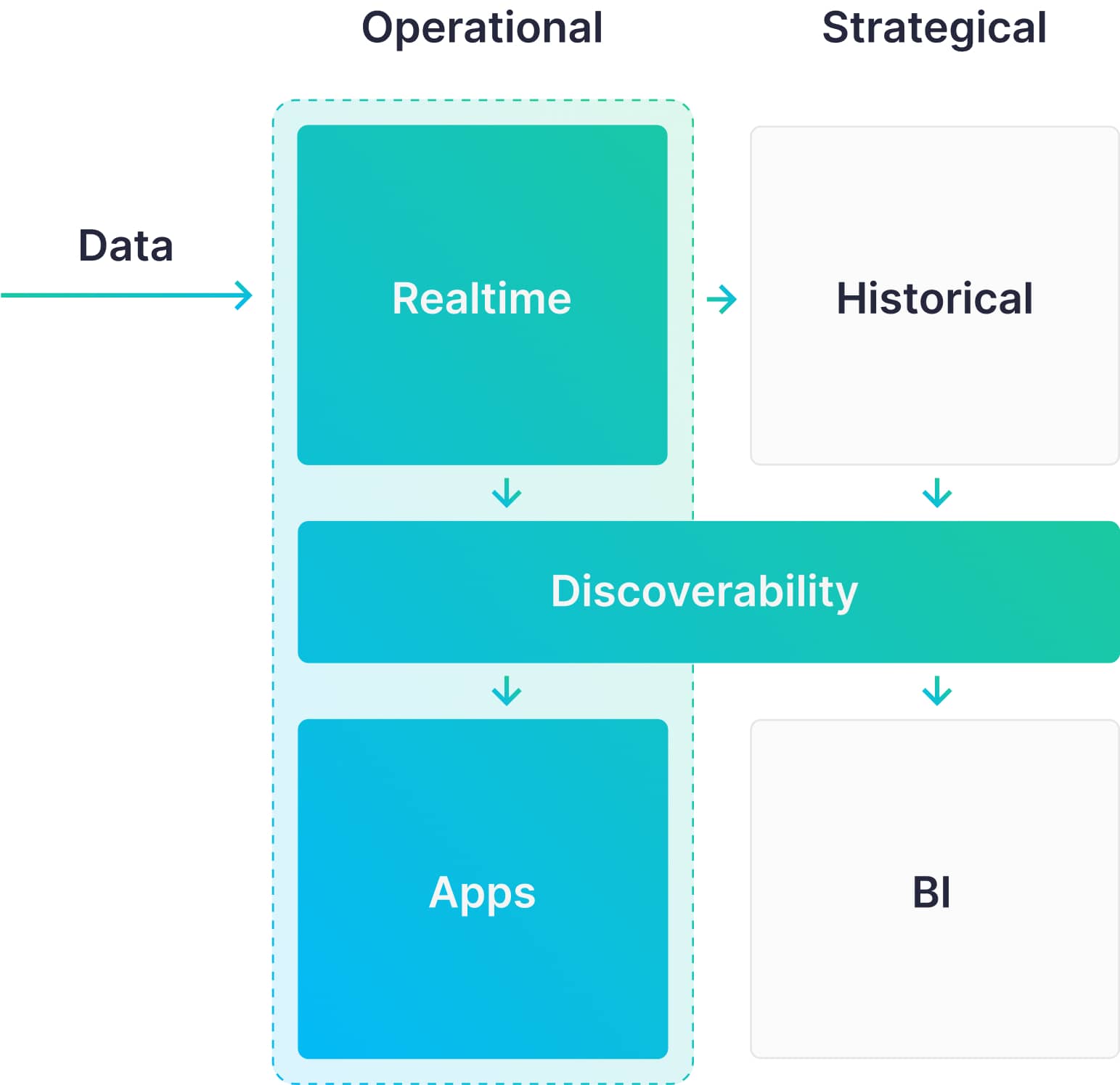
Tinybird + AWS Tools: A complete data architecture
Most businesses have both analytical and operational use cases. In the case of Nikidas, the analytical use case with AWS tools involves business intelligence where strategic decisions made on protracted time scales impact the business trajectory. The operational use case with Tinybird involves day-to-day processes where split-second decisions directly impact revenue growth and real-time profit and loss outcomes. Combining AWS cloud tools Kinesis + S3 + Glue + Athena and Tinybird into a unified data architecture leverages the strengths of each architecture, setting the business up for long-term success based on data-driven strategic and operational decisions.
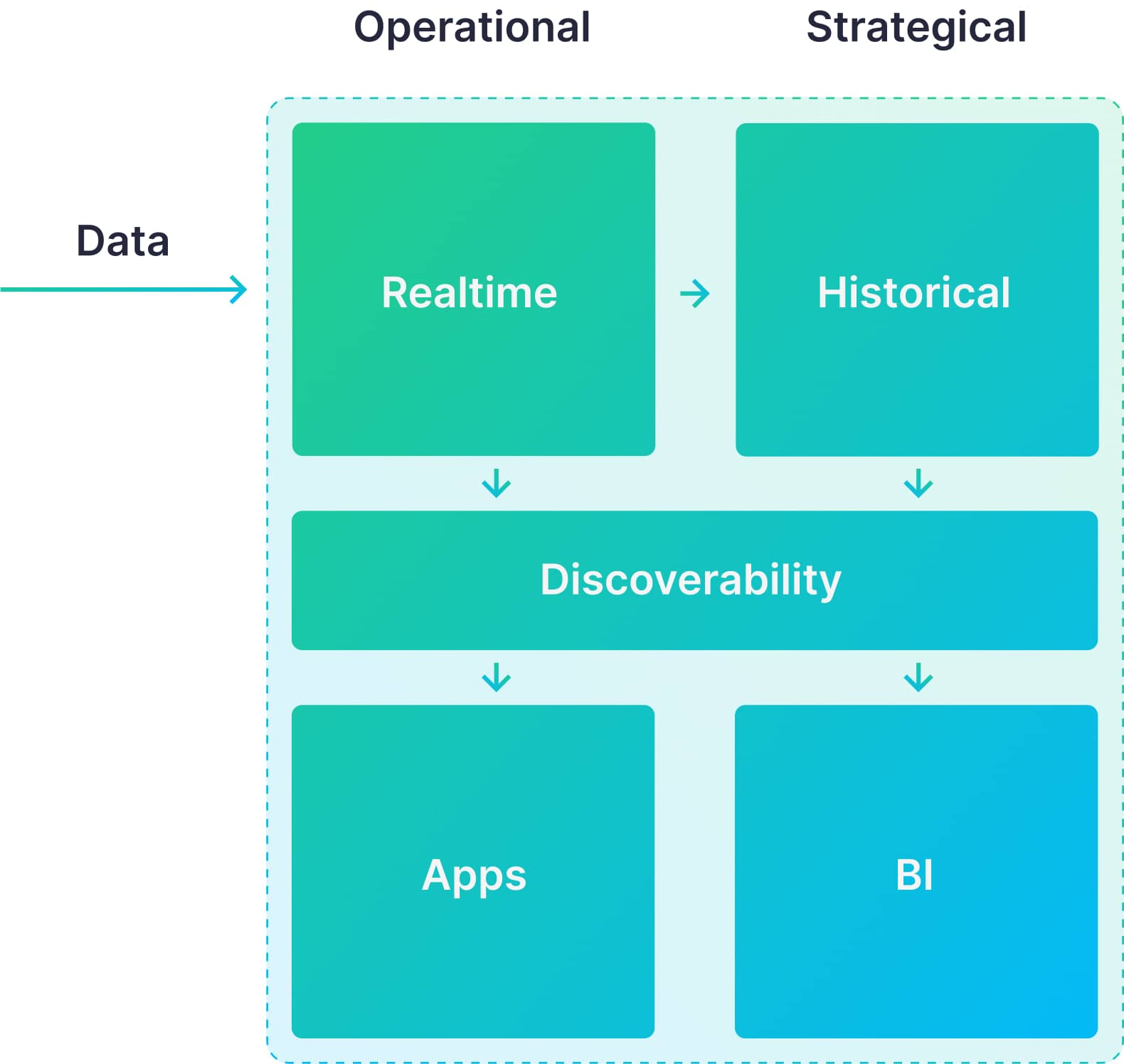
If you're a data engineer or developer building on AWS, and you want to develop real-time applications, consider using Tinybird. You can deploy your Tinybird Workspaces on AWS, ingest data from different AWS systems like S3, Kinesis, SNS, or MSK, and build real-time, scalable APIs to support your application development.
You can sign up for free here (no credit card required, no time limit). Or, if you'd like to dig deeper into your specific use case with a real-time data engineer, request a demo and we'll help you build out a proof of concept in a few weeks (or less).