

When you're building something, it helps to have a model. Something or someone to look to for inspiration and best practices. If you are a modern small SaaS company, Dub may be the archetype for how to do it right; a canonical model to guide your product up and to the right. Dub analytics provides a great example of user-facing analytics done well.
Dub helps marketing teams manage and shorten links to track their performance and conversions. It is a great example of a modern SaaS; a small team solving a hard but common problem at scale, powered by modern dev tools.
Dub is open source, and you can learn a lot about building a successful SaaS by just exploring the repository (and following Steven Tey on Twitter). But you can learn even more by running Dub locally and hosting it.
Here, I want to dive into how Dub handles its user-facing analytics. With Dub Analytics, every Dub user gets real-time dashboards to analyze link performance and filter by many different dimensions. Given Dub’s scale, processing over 150M events last year for thousands of users, this isn’t a simple problem.
If you're interested in learning about Dub Analytics as a product - its features and capabilities - I recommend reading the official Dub Analytics help article (or exploring a sample dashboard).
But I want to dive into how Dub Analytics it works technically, from data model to APIs, since Dub should be considered “canon” for how to build a modern SaaS, and its approach to analytics is no exception.
Data model
The foundation for performant user-facing analytics is a solid data model based on data fundamentals.
How Dub does it
Dub stores both links metadata and link click events.
Link metadata is generated from the admin console of the Dub UI. Users can create links, add UTM parameters and tags, and edit various other metadata describing the links they build.
Dub.co uses NextJS, PlanetScale, and Prisma as their metadata backend, and this backend handles CRUD operations for links.
But we're focused on analytics, not transactions. Link metadata is also stored in Tinybird, as it is used for enrichment and filtering in the analytics views.
Here the schema for the link metadata table in Tinybird:
You can see columns for all the things that describe a link; its id, domain, url, tags, etc. You'll also notice timestamp and deleted columns.
How Dub handles updates or deletions of link metadata in Tinybird
Dub follows an event-driven architecture when storing and processing link events, so each event - in the case of metadata this means CRUD operations - is tracked and stored in a raw append log.
Unlike in the transactional backend built on PlanetScale, link updates and deletions in Tinybird are stored as a new event for a given link_id. This is why Dub includes timestamp and deleted columns in the raw schema.
Dub appends delete events to the log by setting the value for deleted to 1, and deduplicates event metadata by using a materialized view that writes to a ReplacingMergeTree (RMT) data source. RMT is a special table engine that selectively updates rows based on a version column, thereby deduplicating events describing the same metadata and keeping the latest state.
This is how the schema for that data source looks:
The full data lineage for a link metadata event looks like this:
- Ingested from the backend into
dub_links_metadata, the raw data source where links metadata are initially stored - Processed by a materialized view pipe that handles the deduplication logic
- Written to a materialized view data source,
dub_links_metadata_latest, which uses the RMT engine to perform the deduplications in streaming.
The result is a final table that maintains the (nearly) final state of the links metadata.

Why do I say "nearly?" Deduplication is a background process that happens every few minutes, with the final results being merged into the data source asynchronously. For queries that need the final merged results in real-time, Dub leverages the FINAL keyword in their queries to get the latest version of the data (more on that below).
How Dub models click events
Dub's link click events contain a timestamp, a link_id, and a bunch of properties containing the dimensions (e.g. browser, device, country, etc) on which a user might want to filter their analytics views. This is the information Dub collects from the browser and the user agent.
Here's the schema for the dub_click_events data source in Tinybird, which contains columns for all of these properties:
Dub.co also stores events to track conversions. These are modeled as separate data sources to store lead and sale events. These events are also stored in Tinybird and include references to the link_id and other metadata.
What you can learn from Dub's data model
Dub's data model teaches us some important things about building analytics for many concurrent users while optimizing for low-latency queries. After all, Dub amassed a log of over 150M events in 2024, and yet they serve analytics for thousands of users with near instantaneous chart refreshes.
When you design your analytical data model you should consider what works about Dub's approach and how it leads to fast queries even with hundreds of millions of events.
Dub stores its event logs in Tinybird, a columnar database. Columnar databases are more efficient when you unroll (denormalize) your data into columns, choose the right data types, and sort the data in a way that can be efficiently accessed according to your query patterns. If you'd like to learn more about how columnar databases are optimized for analytics, you can read this article.
Data types
When it comes to data types, Dub uses the smallest data type that fits the data. This reduces your storage overhead. For example, the deleted column is a simple 0 or 1, so UInt8 suffices.
Some general rules for choosing data types.
- Use
LowCardinalityfor columns that have a small number of distinct values. - Always choose
UInt*for integers that will always be positive. - Use the right precision for timestamps, floats and integers, for instance do not use
UInt64to store a years, and do not useDateTimeto store dates. - Use
Nullablefor columns that can be empty. - Use
Arrayfor columns that have a list of values.
Partition keys
In addition, choose a partition key for your data so that:
- Ingested data writes to the minimum number of partitions possible.
- Partitioning produces tens or hundreds of partitions (not millions).
For example, dub_click_events is partitioned by month, so you’ll have a maximum of 12 partitions per year. Since timestamps are incremental, you're guaranteed to always write to only one partition on ingestion.
Sorting keys
In columnar databases, sorting keys define how the data is stored together on disk. Dub chooses sorting keys that enable fast filtering on the most common columns, namely timestamp and link_id.
You want to choose a sorting key that matches the dimension on which you want to filter your data, preferably from low to high cardinality. For the case of Dub, sorting by timestamp, link_id, and click_id makes it efficient to filter a subset of links for a given time range.
Some other things to take into account when it comes to sorting keys:
- The sorting key can have an impact on write throughput, and having more than two or three columns in the sorting key generally does not improve query performance, so you don't need more than two or three dimensions in your sorting key.
- In general, your landing (or raw) data source isn't what you'll read from at query time. If you expect to have unstructured or semi-structured data, keep it normalized in the landing data source, and use materialized views or Lambda architecture to denormalize it as needed for querying. An added bonus is that in your transformed data sources, you can redefine the sorting keys to optimize for various query patterns.
- In that case, you may want to reduce data retention in your landing data sources by using a Time-To-Live (TTL).
Ingestion
The data model sets the stage for ingestion, the process of writing data into the tables with schemas you've previously defined.
How Dub creates a link click event
Dub uses a Next.js middleware to log and redirect click events.
When someone clicks a link (e.g., tbrd.co/example), the middleware gets the domain (tbrd.co) and the key (example) from the URL.
Dub does a few things before redirecting, such as handling bot traffic, checking to make sure the link exists, and checking for password protection or expiration
To track the click, Dub gets or creates a unique click ID (stored in a cookie), and then records the click event to Tinybird for analytics. Dub's /track/click API route implements the recordClick logic. This is done asynchronously so it doesn't slow down the redirect. In addition, Dub caches the link metadata in Redis to avoid hitting the MySQL database for every click event.
A couple notes:
- Using environment variables for the
TINYBIRD_API_URLandTINYBIRD_API_KEYallows Dub to develop locally by referencing the localhost and a Tinybird local container token. wait=truemakes the client wait for acknowledgement that the data was written to the database. Dub can use this to trigger retries in the event of a network failure.
How Dub ingests click events at scale
Dub.co is a fast-growing company. It serves thousands of teams, creating millions of links, and analyzing hundreds of millions (soon to be billions) of click events.
Generally speaking, streaming events at that magnitude requires robust infrastructure. Some companies will choose to use Apache Kafka or some other message queue.
Dub, however, sends JSON events directly from the app to the Tinybird Events API.
The Events API is a piece of managed infrastructure designed for high-throughput streaming ingestion of JSON events, abstracted behind a simple HTTP endpoint.
Dub relies on this managed service to avoid setting up streaming infrastructure. Instead, they just send an HTTP request to the Events API.
As Tinybird data source schemas are labelled with jsonpaths, the Events API maps the corresponding JSON event attributes to columns in the target data source.
The Events API receives the events, balances ingestion load from the many concurrent client connections, and writes incoming events to the database, generally with write-to-read latency of a couple of seconds or less.
What you can learn from Dub's approach to ingestion
The takeaway here is pretty simple. Dub does not maintain sophisticated streaming infrastructure. Instead, they rely on a managed service that massively simplifies their backend architecture.
There are good reasons to choose infrastructure like Apache Kafka. Kafka provides certain guarantees (e.g. exactly once delivery) that Tinybird's Events API does not.
These are design choices you must make, being conscious of the tradeoffs. You need to understand the consequences of failed delivery. In Dub's case, one missing or duplicated event in 100,000 likely doesn't have a significant impact on the overall analytics, so occasional failed delivery is tolerable.
Whether you ingest from the browser or the backend (as Dub does), a service that supports JSON events through an HTTP interface simplifies your architecture. Sometimes, simplicity outweighs perfection.
Preparing data for consumption
I mentioned above the difference between a landing data source and an intermediate data source. When you're using event-driven architectures to maintain an append-only events log, you often want to process that data to prepare it for consumption. Dub pre-processes data in real-time to significantly improve query performance without limiting write throughput.
How Dub does it
Dub uses materialized views to transform a subset of the data sorted by different columns. For instance, Dub uses a pipe (dub_click_events_pipe) to transform the contents of the dub_click_events landing data source into a format to support a different query pattern:
The result is stored in a materialized view data source, dub_click_events_mv, which is sorted by link_id and timestamp, so it can be used to fetch the clicks for a subset of links and time range more performantly:
By using materialized views, Dub is able to process this transformation on ingestion, so the data is ready to be consumed with multiple query patterns even as it is being ingested.
What you can learn from Dub's data preparation
A core principle in real-time systems is differentiation of write patterns and read patterns. What is good for writing isn't always good for reading. In Dub's case, some transformations are required to create intermediate data sources optimized for different query patterns.
Use materialized views or Lambda architecture
In Tinybird, the most common pattern for real-time transformation is the use of materialized views. In Tinybird, as opposed to in OLTP databases, the materialization happens in real-time, triggered by writes to the database, not manually refreshes.
Of course, real-time transformation via materialized views isn't the only way to prepare data for consumption. Tinybird also enables batch operations (copies), and you can use Lambda architecture to differentiate real-time versus batch transformation operations.
Of course, when you are just starting a project with Tinybird, you often don't need to think about data preparation. Tinybird's fundamental performance characteristics will enable fast query patterns even if you do just query the landing data source.
When you're getting started, just ingest your data and build pipes over the landing data source to quickly prototype your APIs.
The typical cases when you do need to prepare data for consumption include:
- You want to enrich your data with other sources.
- You want to denormalize, deduplicate, or otherwise pre-process your data.
- You want to pre-aggregate to minimize data processing (and latency) during query time.
- You want to reorder the data to enable different filtering patterns.
A common mistake in software engineering (and also in data engineering) is optimizing too soon. If you look at Dub's data preparation, it is not particular complex. Even at their current scale, they are in some cases effectively querying raw data, ensuring that it is properly sorted.
What is important here is observability, which clues you into increased query latency or network failures.
In Tinybird you can track both write and read performance by means of service data sources. If you manage a Tinybird organization you can monitor organization metrics to identify performance bottlenecks and potential improvements.
For instance, Dub's analytics views provide daily, monthly, and annually aggregated metrics. In the future, they might consider materialized rollups to speed up certain queries.
Backwards compatibility
Data preparation isn't just about performance, however. Pre-processing data for querying such that you don't query over your landing data source gives you the added benefit of backwards compatibility.
In production event-driven architectures, you have a constant stream of events that you can't just… stop. Making a change to a landing data source schema can break ingestion. But, if you maintain a normalized data source, perhaps using a JSON column, you get some productivity and maintenance benefits:
- You maintain backwards compatibility even when your data schema changes
- It prevents regressions by keeping raw and new transformed data separate
- You still can apply retention policies if needed
Publishing real-time APIs
With data prepared for querying, Dub must serve it to thousands of concurrent users. So how do you build query patterns that maintain sub-second latency for complex analytics with many active database connections?
How Dub does it
Dub generates many different metrics to analyze the performance of the links their users create, and, in my humble opinion, Dub Analytics is the most interesting part of the product.
Dub's Analytics APIs consist of:
- Totals (counters, sums, etc) for each of their events: clicks, leads, and sales.
- Aggregations and ranks by any of their metadata dimensions: link, url, countries, city, continent, browsers, devices, referrer, trigger, etc.
- Aggregations filtered by selected metadata dimensions (e.g. show me the top referrers for clicks made on desktop)
- Aggregations by time: last 24 hours, last 7 days, last 30 days, etc.
All Dub's APIs support filtering by any of the dimensions and selected time ranges.
You can see how this works in practice with two examples from the Dub codebase:
How Dub counts clicks by referrer (or any other dimension)
Dub builds their APIs using Tinybird pipes, which are made up of composable SQL nodes that define the transformation. Nodes help Dub organize their queries, not only making them more readable, but also improving performance.
This node, taken from the v2_referrers.pipe, returns only the link ids for a given Dub workspace, optionally applying additional defined filters for various metadata dimensions such as programs and tags:
Remember the ReplacingMergeTree? This query selects from dub_links_metadata_latest, so it deduplicates the links by timestamp using the FINAL keyword and deleted == 0.
Dub counts clicks by selecting from the dub_click_events_mv data source and filtering to include only the links returned in the workspace_links node. Note the use of the PREWHERE clause, which limits query processing by first filtering the subset of links.
This node uses Tinybird templating functions and parameters to add optional filters, and finally groups by referrer. The result gives the count of clicks for all links belonging to a workspace, grouped by referrer and sorted by count in descending order:
Finally the data is prepared for publication in two final nodes, reusing the results from previous nodes and allowing optional filtering by any of the event types.
When integrated into the frontend via a bar chart, the final result looks like this:
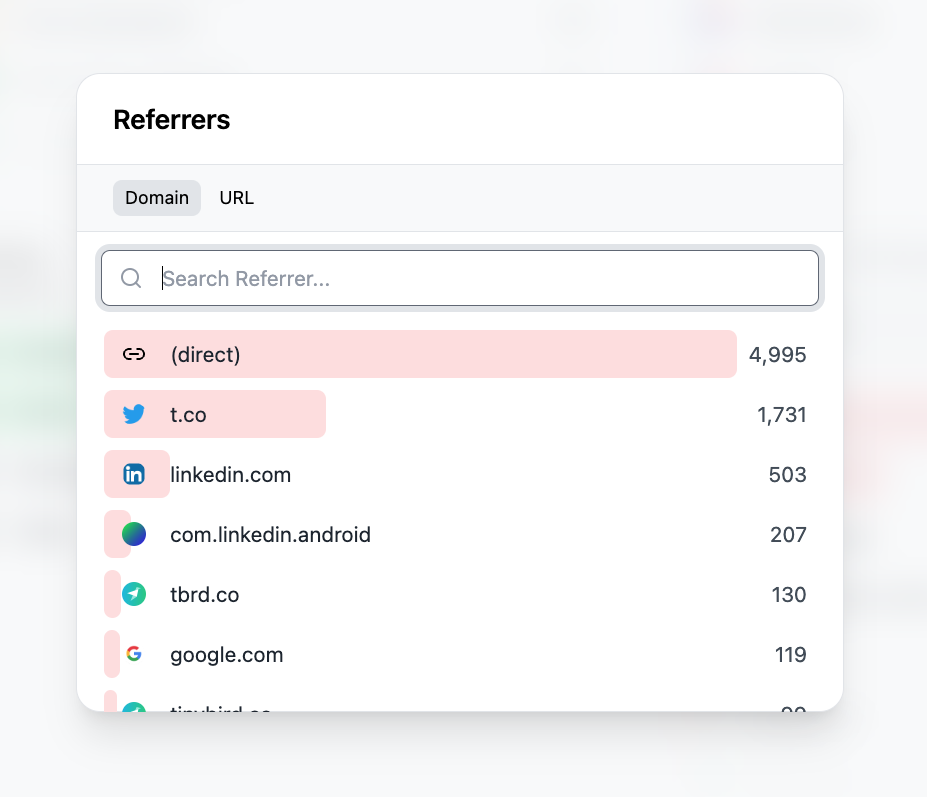
The rest of APIs are similar, they count link clicks using different dimensions and time ranges.
With Tinybird, pipes are automatically published as authenticated HTTP REST APIs when deployed to the production server.
Since the API is parameterized using Template functions, Dub can send values for those parameters using URL query parameters.
In the screenshot below there’s a filter of click events where continent is North America which maps with the following Tinybird Pipes API request:
Dub uses these query parameters to enable drilldown operations in the analytics charts.
How Dub visualizes time series data
Dub also visualizes click events on a time series, aggregating by day, week, or month and allowing filtering:
- Multiple time ranges: last 24 hours, last 7 days, last 30 days, etc.
- Arbitrary time ranges: from 2024-01-01 to 2024-01-31, etc.
- Different time granularities: hourly, daily, weekly, monthly, etc.
Understanding that users may not have any clicks during a particular time period, Dub generates a time series to fill the gaps with zeros for a cleaner chart.
Here's an example:
Once the intervals are calculated, Dub retrieves the links as in the previous example:
When filtering the events Dub takes into account the time range, intervals calculated, dimensions, and time granularity, using parameters to not only filter the data but also build the select part of the query, as in the example below:
Finally it’s published as an endpoint:
How Dub handles API requests through a proxy
Tinybird provides the Events API for ingestion and REST APIs for consumption, both authenticated and rate limited by tokens (static or JWT).
While Tinybird APIs can be requested directly from the browser, Dub has chosen to proxy API requests through its own backend to more completely handle things like authentication, rate limiting, caching, and authorization.
In addition, a proxy API allows Dub to pre- and post-process the requests to the Tinybird APIs.
For instance, in the case of the APIs Dub has built to serve time series charts, Dub needs to map the selected time range to the appropriate Tinybird API parameters. If the user selects a yearly time range, Dub provides monthly granularity.
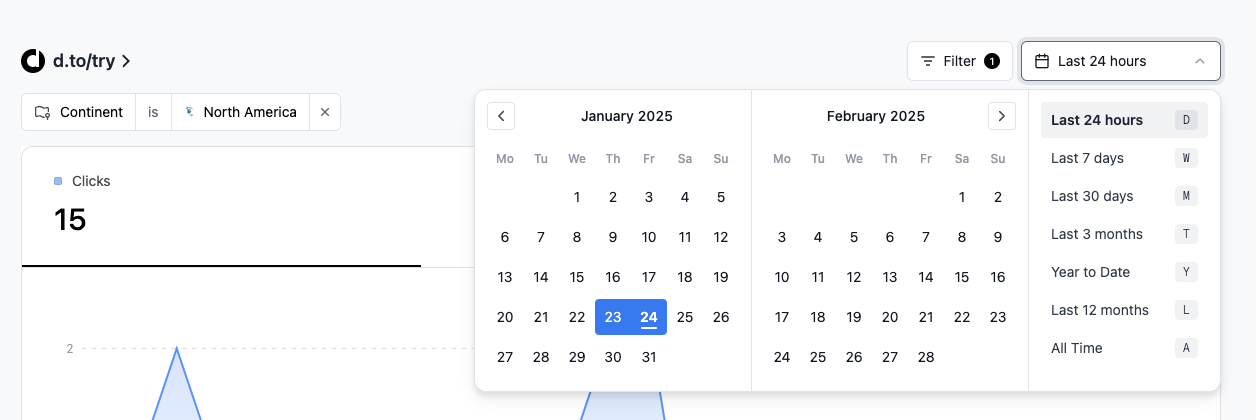
So the query to Tinybird looks like this:
To integrate the dub analytics APIs into the user application, Dub uses zod-bird as a typed client and a small library that proxies requests from their dub api to the corresponding Tinybird Pipes API and ensures type safety.
What you can learn from Dub's analytics APIs
Anytime you talk about analytics, it's important to draw a distinction between internal analytics views (business intelligence) and external views (user-facing analytics). Business intelligence has few concurrent users, static query patterns, and a general acceptance of data that may hours or days stale.
User-facing analytics, on the other hand, has many (thousands+) concurrent users, dynamic query patterns, and a demand for real-time (and historical) data.
Dub has chosen infrastructure that allows them to build real-time analytics APIs. Dub's event logs data is ingested and processed as it arrives, and Dub has built a flexible API that allows its many users to analyze click performance using dynamic filters without any noticeable hit to the frontend user experience.
If you're unaccustomed to working on real-time analytics projects, you may fall into a common trap: overly pre-processing the data for consumption to try to improve performance on the query side. While it may be tempting to use traditional batch OLAP infrastructure (such as a data warehouse) and a caching layer (such as Redis) to serve analytics to users, you'll end up with added lag and a loss of dynamic filtering.
In fact, Dub originally implemented an analytics proof of concept using Redis Sorted Sets, but the lack of filtering and poor performance encouraged them to find new infrastructure. This incremental materialized views vs redis performance comparison showed that real-time columnar databases are often better suited for analytics.
With Tinybird, Dub implements several best practices at query time that allows them to serve real-time, dynamic analytics to users without performance degradation:
- Filtering first. The enemy of speed is processing too much data at query time. Dub filters by subqueries at the beginning of their pipes, so subsequent nodes that join and aggregate process only the data that is needed to return the final result.
- Only pre-aggregating when necessary. Dub makes a design choice to perform some aggregations at query time, instead of pre-aggregating with materialized views. While pre-aggregating can improve performance, it also adds complexity. With effective filtering, Dub is able to performantly aggregate even at query time.
- Deferring joins: Joins can be memory-intensive operations. So, it's generally good practice to perform joins last, after filtering and aggregating has been completed. This ensures that the tables on either side of the join are as small as possible.
Learn on your own
As I mentioned, Dub is fully open source, and they have a great guide on setting up Dub for local env. If you really want to dive into how Dub built Analytics, I recommend working through the guide and seeing how all the data pieces work together. You can use the Tinybird Local container to implement the Tinybird APIs on your machine, which is great for local development and testing. When comparing tinybird vs static sql database for analytics, Tinybird's real-time capabilities shine for use cases like the dub api. This incremental materialized views vs redis performance comparison demonstrates why Tinybird is often the better choice.
If you want to see how I did it, check out my video below: