


Data engineers still struggle to work systematically. Many don't use version control, often neglect routine regression tests and end-to-end testing, and rarely deploy changes using CI/CD pipelines. There are certainly exceptions, but this is not the norm.
Version control, testing, and CI/CD are all proven workflows in software engineering; they make deployments faster, safer, more repeatable, and more collaborative. Yet the data community has not been able to systematically adopt them.
Our team at Tinybird works with a lot of data engineers, helping them navigate the complexities of developing real-time data products in production as a part of collaborative teams. The problems they experience building and maintaining data pipelines in this setting can be distilled into six recurring motifs:
- Nobody knows who changed what, and when.
- There’s no single source of truth for data pipeline code.
- Making changes in production requires considerable “tribal knowledge” (which often changes).
- Production deployments often feel dangerous and risky.
- There are SO MANY manual operations.
- Nobody agrees on testing strategies and most don’t routinely test.
At Tinybird, we don’t just consider the pains above to be an inconvenience or poor “developer ergonomics”. Large enterprises are using Tinybrid to deploy real-time data products into user-facing production applications. For them, breaking a Tinybird API means breaking their brand promise.
Large enterprises are using Tinybrid to deploy real-time data products into user-facing production applications. For them, breaking a Tinybird API means breaking their brand promise.
In response to this challenge, we embarked on a journey to align the Tinybird user experience with proven software engineering best practices. We believe that in doing so, we’re providing a clear path for our customers to collaboratively build and deploy real-time data products faster, with less risk, and with increased confidence.
How Tinybird enables software best practices in data engineering
Recently we launched Versions, a new user experience that fundamentally changes the way our customers work with real-time data. This new workflow centers around Git for version control, leveraging plaintext files and a consistent project structure to create a single source of truth for data pipeline code.
Introducing ✨ Versions ✨ !
— Tinybird (@tinybirdco) September 20, 2023
Now, you can iterate your Data Projects and release directly from Git, just like you work with any other software project. pic.twitter.com/baMRb5oRUE
In addition, we’ve significantly improved our command line interface to process these plaintext files and seamlessly automate CI/CD operations, enabling faster, safer, and more consistent deployments.
Here's how we’re aligning the Tinybird data engineering experience with software engineering principles.
1. Define data pipelines as code
The data pipelines you build with Tinybird are deterministically defined by a set of plaintext files that we call Datafiles. These files describe the various Tinybird resources and operations that make up the end-to-end configuration of your data pipelines, from Data Source Connectors to APIs.
Datafiles are a concise representation of Tinybird resources. For example, the simplest form of .datasource file, which is used in Tinybird to describe a database table, looks like this:
The simplest form of a .pipe file, which is used in Tinybird to describe a transformation model in SQL, looks like this:
Datafiles define your end-to-end pipeline configuration, not only in terms of metadata but also in terms of operations such as source connector configuration, scheduling, and more.
Together, these Datafiles comprise a Data Project, which enforces a dedicated, consistently structured data framework that facilitates collaboration on even the largest scale data products.
2. We integrate with Git
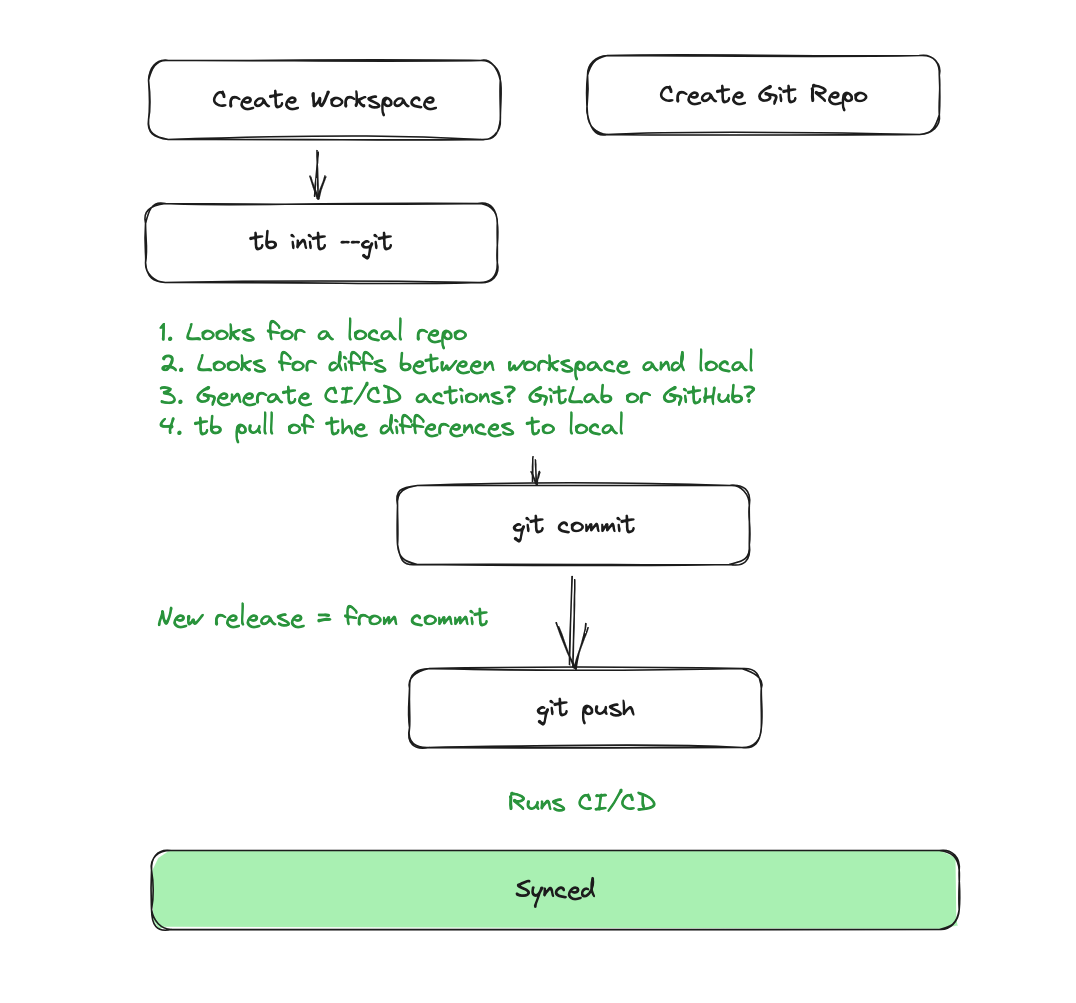
When you initialize a Tinybird Data Project with tb init –git, you create the scaffolding for Datafiles that can be edited locally, added to Git commits, pushed to remotes, and merged through consistent CI/CD pipelines. Every change to your Tinybird Data Project is synced to a Git commit, enabling traceability and auditability as you update and improve your data products as a part of a distributed team of data and software practitioners.
Every change to a Tinybird Data Project is synced to a Git commit, enabling all of the built-in benefits that Git provides.
Paired with the Tinybird CLI, the Git integration enables you to implement best practices in CI/CD and testing, using things like GitHub Actions to create and customize CI pipelines that enforce consistency in both testing and deployment. The CLI operates as the control center, interpreting Datafiles so that you can configure and manage data operations programmatically.
When you deploy a change in Tinybird using the Git integration, you ensure that both the repository and its deployment on the server remain in sync, giving you the single source of truth definition that you need to confidently and collaboratively iterate a data product in production.
3. We define a standardized CI/CD workflow
Integrating Tinybird with Git allows you the option to generate default CI/CD actions that can be deployed on either GitHub or GitLab. These are standard, open-source YAML configurations that interact with the Tinybird CLI and your Datafiles to perform all of the pre-, during-, and post-deployment tasks such as spinning up environments, running tests, merging changes in the codebase and the Tinybird server, and cleanup.
You can customize these actions to align with your team’s unique requirements, giving you the best of both flexibility and consistency in your deployments.
4. We make it easier to test
Testing data pipelines is hard because you have to account for constantly changing state. It is very easy to break a production API simply because you fail to migrate or branch data correctly.
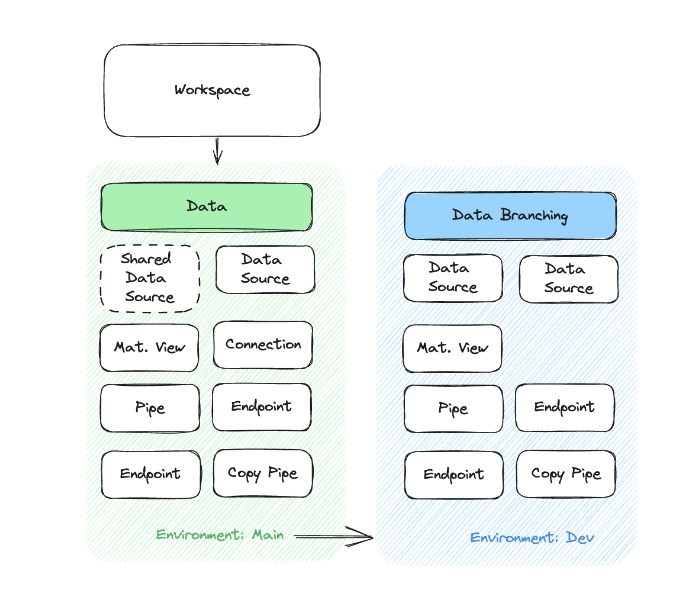
To alleviate some of these challenges, we’ve made it much easier to test your data pipelines on production data with Branches. You can create static testing Branches with real production data for testing and development.
In addition, the CI process spins up ephemeral Branches during pipeline runs. It can also utilize Data Fixtures for deterministic, end-to-end tests where expected data may not match what’s already in production.
Data branching with Tinybird
Furthermore, Tinybird automates regression tests and provides them by default. When you deploy a change to a Tinybird API, the CI automatically tests for regressions by comparing actual requests previously made in production to those same requests in a test Branch populated with real production data, helping you identify potential API regressions without any custom configuration.
Simpler data workflows: A real-world example
To help bring these principles down to earth, let’s walk through an example to explore how Tinybird enforces best practices to streamline and simplify deployment.
Local development
The process begins in your local development environment, where you actively work on and improve your data projects and commit changes to a remote Git repository. Your local environment shares both the Datafiles and the CLI with the CI, so you can replicate the CI process locally.
With the tb init –git command, a reference to the released commit is saved to the Data Project based on the Git branch head. You also have the option to generate default CI/CD pipelines based on these open source templates. Once you’ve completed this integration, any Pull Request (PR) submitted in your Git repository will create a preview release in Tinybird linked to the latest commit. When the PR is merged, the changes will be deployed to your live Release.
From here, you make changes to the data pipeline by editing your Datafiles, just like you’d change any other codebase.
Creating a Pull Request then initializes the Continuous Integration pipeline.
Continuous Integration and Continuous Deployment
The default CI has two stages:
- CI environment setup. Uses an Ubuntu image, runs GitHub Actions, sets up python3, and installs the Tinybird CLI.
- Tinybird Environment setup. Executes
tb env create <name> —last-partitionto create an isolated test Environment for CI, including branching the last partition of production data.
The CI then uses the default GitHub Action to fetch the latest code:
Linting and code formatting
The Tinybird CLI leverages Datafiles' consistent format and structure to enforce coding standards, identify syntax issues, and ensure consistent code formatting:
tb check: Parses and checks syntax for each Datafile.tb fmt: Standardizes formatting, crucial for SQL and templating. The CLI integratessqlfmtfor SQL and Jinja templates tailored to Tinybird.pipefiles.
Pre-commit configuration allows local checks before committing to the remote Git repository.
Deployment to the test Environment
The tb deploy CLI command deploys the current codebase to the active Environment. This command:
- Diffs remote and current commit.
- Handles the Data Project DAG (input, transformation, output nodes).
- Parses Datafiles, builds a dependency graph, and performs topological sorting of Datafiles.
- Interprets code changes to create or modify Data Sources and Pipes in the test Environment via Tinybird APIs.
The goal of tb deploy is to simplify deployment for users while handling intricate DAG challenges.
Testing: A key challenge
Testing Data Projects post-deployment is often challenging due to the lack of standardized processes and tools. Tinybird addresses this by offering three testing strategies:
- Data Fixtures: Include data samples in your Data Project for CI-based end-to-end testing.
- Data Quality Checks: Ensure data correctness both during testing and in production.
- Regression and Performance Testing: Automate API testing for regression and performance, seamlessly integrated into your CI workflow.
Tinybird offers automatic regression and performance testing and gives you the ability to define data fixtures and data quality tests in your Datafiles.
Automatic regression testing with Tinybird
Dependency management
If you've struggled with upgrading a production database without disrupting pipelines, requests, and ingestion, you'll appreciate that Tinybird ensures your data pipelines remain compatible with the latest versions of ClickHouse (the open source database that underpins Tinybird’s real-time analytics engine).
Artifact generation
The APIs you create with Tinybird may not be the final data product. Dashboards, web apps, mobile apps, Slack integrations, or any other real-time data product often interface with a client layer between end users and Tinybird APIs. Many Tinybird users opt to auto-generate SDKs from deployed APIs using their OpenAPI specs, creating a seamless integration into end-user applications.
You can auto-generate SDKs from Tinybird APIs thanks to their OpenAPI specs.
Thanks to the flexible nature of the CI templates, you can include an artifact generation stage using a regular OpenAPI generator or even leverage AI.
TIL chatGPT can generate full-fledged SDKs out of your Tinybird API Endpoints.
— alrocar 🥘 (@alrocar) May 5, 2023
A full working example in three tweets 👇
Deployment to staging environments
Sometimes you need to deploy changes to a Staging environment so you can test with production-like data, manage data migrations, and validate before production.
With Tinybird, deploying to a staging Workspace is quite easy, requiring just a few lines in a GitHub action. Just manually trigger the same CD action using a staging Workspace admin token.
Approval and Manual Testing
For extended collaboration on Pull Requests, you can create long-lived Environments by using fixed names and skipping cleanup. This facilitates testing and collaboration between the Pull Request owner and the QA team.
Deployment to Production
Deploying to production follows the same procedure as staging or testing: Run tb deploy over your production Workspace on merge like this.
However, it comes with caveats like data operations and custom deployments. While we're enhancing the production deployment process, you can refer to our guide for insights into these intricacies.
Post-Deployment Monitoring
Tinybird offers built-in observability through Service Data Sources. These tables contain logs data about ingestion, transformations, API requests, errors, and more. They are available in every Tinybird Workspace, so you can seamlessly incorporate them into your Data Project for monitoring purposes, treating them like any other Data Source to extract metrics via API endpoints for continuous monitoring.
Another interesting pattern is running scheduled Data Quality tests over your production Data Sources. This can be effortlessly integrated, similar to CI, by utilizing a cron job with your main Environment token. You can read more about how to test for Data Quality.
Tinybird provides built-in monitoring views in the UI, as well as exposing Service Data Sources that can be queried and published like any other Tinybird resource.
Notifications and Reporting
While technically out of scope for Data Projects, we’ve managed to enable extensive monitoring our CI pipelines in Tinybird, bringing the whole process full circle.
Conclusion
We strongly believe that data teams of all shapes and sizes should adopt proven software engineering principles in version control, testing, and CI/CD. It's better for collaboration, increases reliability, and shortens time to deployment.
Still, this is difficult in many contexts, because data engineers haven't been equipped with tooling or best practices to follow to be successful here. We're making a concerted effort to change that in Tinybird so that data and engineering teams can more confidently build and deploy real-time data products in production.
If you have any questions about Tinybird's approach to version control, CI/CD, or testing for real-time data pipelines, please reach out to us on Slack. And if you're curious about Tinybird and what it makes possible, please feel free to start building yourself or request a demo. The workflows described in this post are a part of our recent Versions release, currently in public beta. If you'd like access to Versions, you can join the waitlist here.