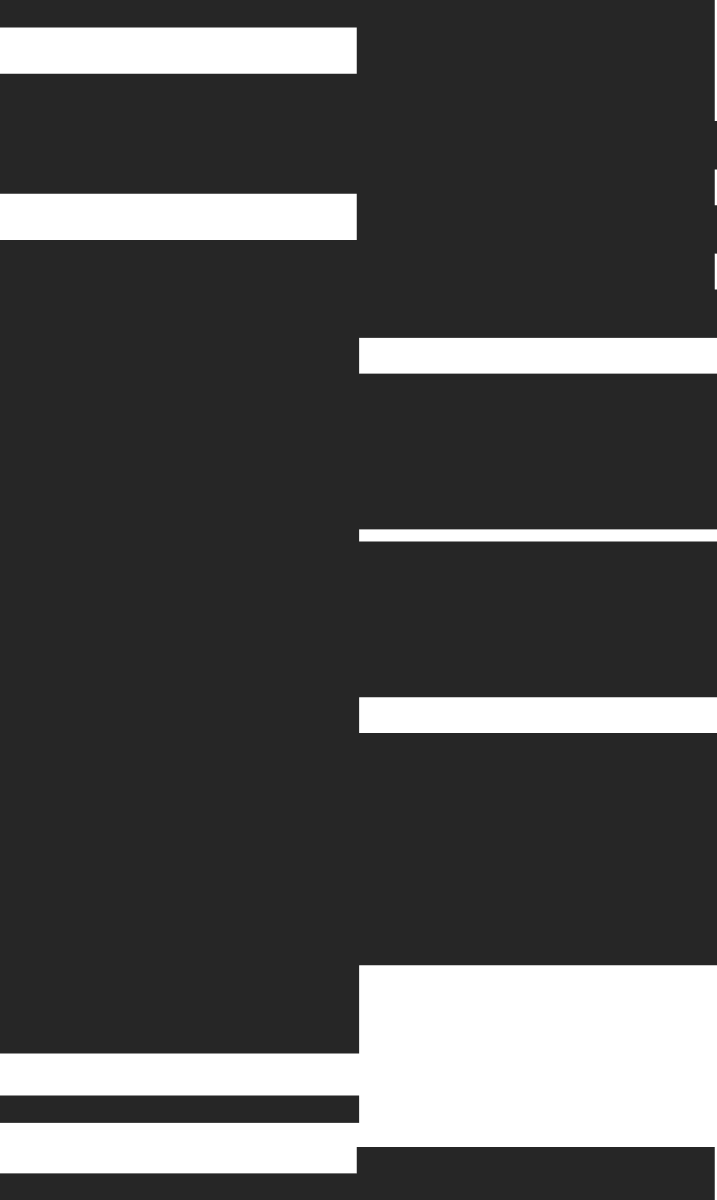
Pipes solve a problem you hit fast in raw SQL: long queries with several CTEs, no easy way to inspect intermediate steps, and no contract for how the query is consumed. A pipe breaks a transformation into named nodes, each a SELECT, where every node can reference the previous one by name. You build incrementally and read top to bottom.
A pipe is also a deployment target. Marking the last node TYPE endpoint publishes it as a parameterized HTTPS API. TYPE materialized writes its output into a target data source on every ingest. TYPE copy runs it on a schedule. TYPE sink pushes the result to an external destination. One file, one transformation, four possible shapes.
Pipes are the layer where SQL becomes a product surface. Data sources are the storage; pipes are how that storage turns into APIs, derived tables, or scheduled exports.
A pipe with two nodes, published as an endpoint
NODE filtered_events
SQL >
%
SELECT *
FROM events
WHERE tenant_id = {{ String(tenant_id) }}
NODE aggregated
SQL >
SELECT
toStartOfMinute(timestamp) AS minute,
count() AS events
FROM filtered_events
GROUP BY minute
ORDER BY minute DESC
TYPE endpoint