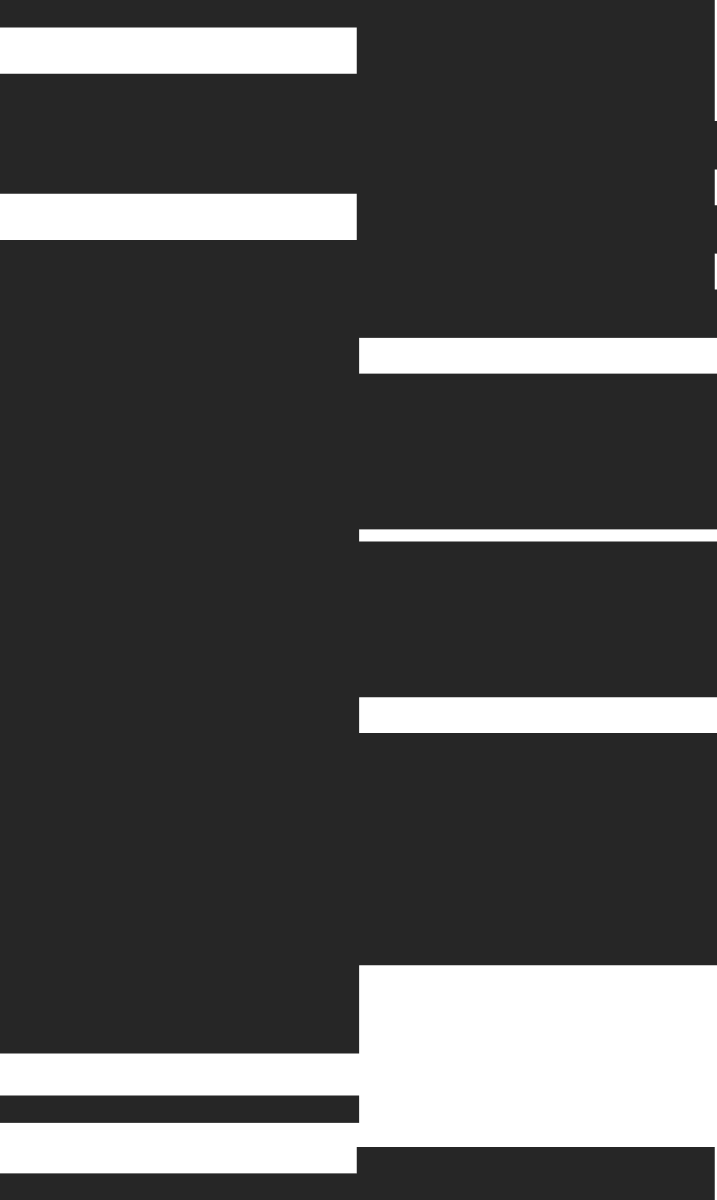
Data Platform

Kafka SQL Real-Time Queries
Fast time-to-value, fully managed and auto-scaled
Real Kafka Use Cases
Your Kafka Pipeline, Without the Ops Pain
scaled to petabytes via Kafka with 7 use cases in 7 months.
ingested
ingested
latency
“Our devs evaluated Pinot, Druid and Tinybird. They preferred Tinybird for performance, reliability, integrations, and developer experience.”

Damian Grech
Director of Engineering, Data Platform at FanDuel

Enterprise features
Why Tinybird
Kafka Connector
| Tinybird Kafka Connector | ClickHouse® OSS Kafka Engine | |
|---|---|---|
Pricing & Support | ||
| Pricing Model | Throughput based | Cluster resource pricing |
| Topic Limit | Unlimited | Limited by infra |
| Enterprise support | ||
Scaling & performance | ||
| Serverless | ||
| Consumer autoscaling | ||
| Compute-storage separation | ||
| Push/Pull Model | Push | Pull |
| Sub-second flushing | ||
Operations & failure handling | ||
| Circuit breaker & Backpressure | ||
| High Availability | Default HA | |
DevEx | ||
| CLI + Tinybird codeData as code | ||
| Environment branchingSecrets, consumer group IDs, etc. | ||
| Schema evolution |

Build for scale
Tinybird Kafka Connector Features
Scaling & performance
- Serverless
- Consumer autoscaling
- Sub-second latency flushing*
Operations & failure handling
- Zero ops (fully managed)
- Debug metadata
- Clear failure modes and recovery paths
Data correctness & offsets
- Offset management
- Builtin backpressure
- Dead letter queue (quarantine)
Enterprise ready
- Schema Registry integration
- Kafka security protocols: SASL/SSL...
- Private network supported*
Observability
- Lag, latency and throughput metrics
- Error logs
- Grafana, Prometheus enabled
Developer experience
- CLI + Agent Skills
- Environments & Data Branching
- Local development + CI/CD
* Talk to us for sizing and enterprise requirements
Get started
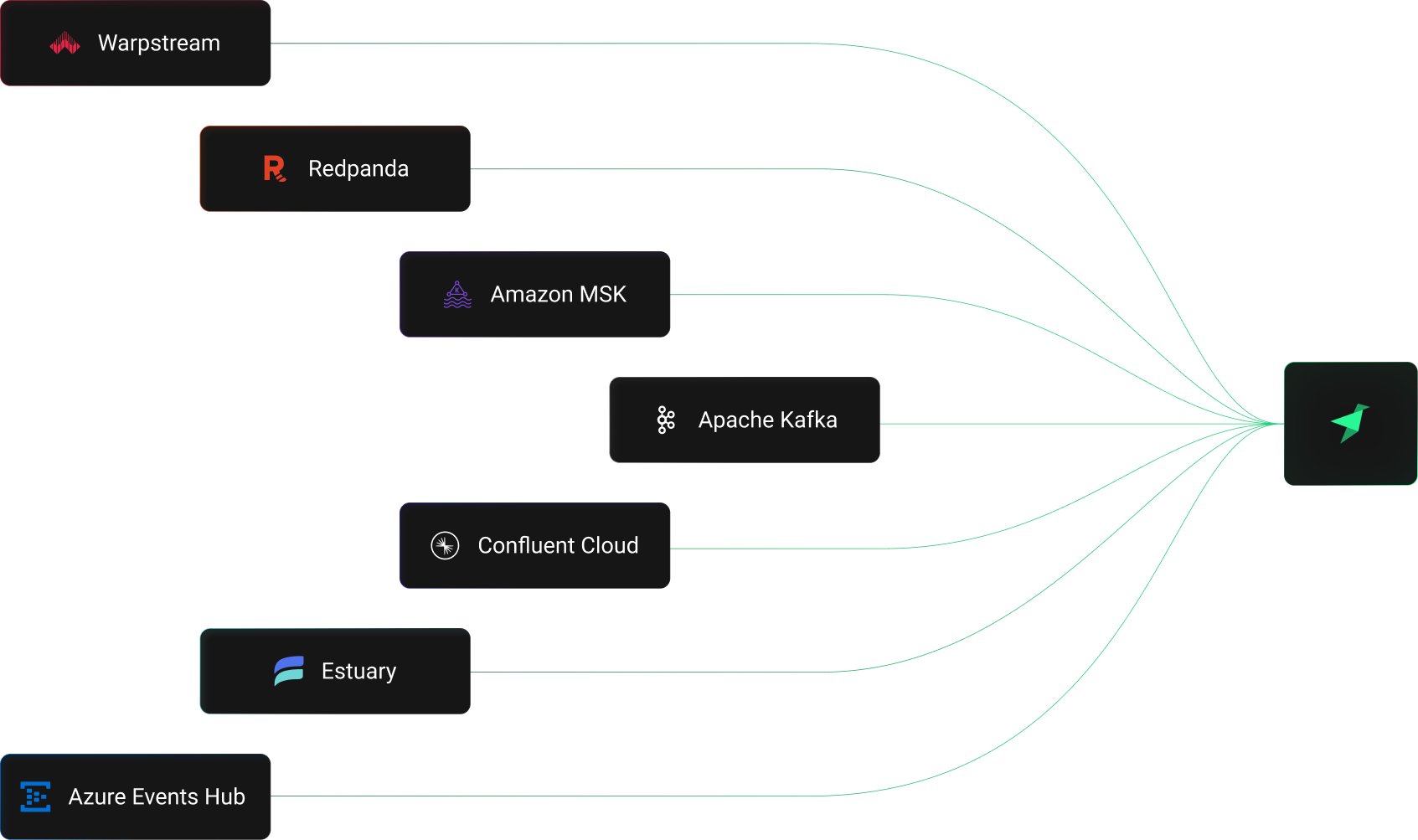
Supported
Kafka vendors
FAQs
How do I create new connections?
Create a Kafka connection using the CLI with `tb datasource create --kafka` for a guided process, or manually create .connection and .datasource files. Your credentials are stored securely as secrets. Tinybird supports multiple authentication methods including SASL for cloud providers like Confluent Cloud, Amazon MSK, and others.
Is it a managed connector or do I have to run something myself?
Tinybird's Kafka connector is fully managed—you don't run anything. We handle consumer autoscaling, offset management, failure recovery, and high availability. Just provide your Kafka credentials and start ingesting.
Can I test ingestion locally or in different environments?
Yes. Tinybird Local is a Docker container that replicates the full Tinybird environment, including Kafka connector support. Use `tb dev` for local development, run tests with `tb test`, and deploy to staging/production environments.
How much can I ingest and how do I manage scale?
Tinybird's Kafka connector is serverless with automatic consumer autoscaling. There's no limit on topics or throughput—we scale based on your workload. The default message size limit is 10MB per message. You don't manage scale; we handle it automatically.
How is it priced?
Tinybird offers plan-based pricing with Free, Developer, SaaS, and Enterprise tiers. Each plan includes vCPU and storage allocations. The Kafka connector is included in all plans. Developer plans support up to 5 Kafka topics; SaaS and Enterprise plans offer unlimited topics.
What plan do I need for X rows/sec or Y GB/day?
The Kafka connector is included in all plans, including the Free tier. Developer plans support up to 5 topics, while SaaS and Enterprise plans offer unlimited topics and dedicated infrastructure for high-throughput workloads. Each plan comes with vCPU and storage allocations that scale with your needs.
What formats are supported?
Tinybird supports JSON and Avro message formats. You can configure the format using KAFKA_VALUE_FORMAT and KAFKA_KEY_FORMAT settings in your datasource file. Compressed messages (gzip) are automatically decoded on ingestion.
Do you support schema registry?
Yes. Tinybird integrates with Confluent Schema Registry for decoding Avro messages. For JSON messages with schema registry, use the KAFKA_VALUE_FORMAT and KAFKA_KEY_FORMAT settings (requires CLI 5.14.0+). Configure your schema registry URL in the .connection file using KAFKA_SCHEMA_REGISTRY_URL.
What happens on ingestion failure?
Messages that fail to match your schema are automatically sent to a quarantine data source (similar to a dead letter queue). Quarantine preserves the original message plus error details, allowing you to inspect issues and replay data after fixing problems. Built-in circuit breakers and backpressure prevent cascading failures.
How do you handle schema evolution?
Use the FORWARD_QUERY instruction in your .datasource file to define how existing data transforms to your new schema. When you deploy, Tinybird applies schema changes with zero downtime—your data remains queryable throughout the migration.
What are the main limits and quotas?
Key limits: 10MB max message size, rate limits on API requests (HTTP 429 when exceeded), and 10-second default query timeout (configurable on paid plans). Messages exceeding limits are quarantined, not dropped.

Ship real-time features from Kafka in hours, not quarters
- Start with a 10-minute guide
- Read the deep dive: How we built the connector
- Compare: Kafka Engine vs Tinybird Connector
- Learn how to build and end to end use case in 15 minutes

